Horse racing. There’s a lot of numbers and statistics involved, but some of the best advice is probably the simplest: don’t do it unless you know more than everyone else in the betting pool.
I’m not looking to become a gambling statistician, but a friend requested a post on the topic of horse racing and I figured it would be a fun topic to take a look at. I’m not planning on looking for anything that will make me rich, just taking a look at what some of the numbers can tell us. I’m also betting (haha) that I’ll only touch on the surface and basics today, look at one quick example, and maybe revisit the topic in another post some day.
One of the ways that you can classify gambling games is who you’re betting against. In games like slot machines or roulette, you’re playing against the house. The amount of money that can be won is only capped by the table limits. If you’re playing roulette and you bet $10,000 dollars on red 12 you win $360,000 from the house. There doesn’t have to be anyone else playing, and the amount of other money on the table doesn’t change your payout. The house has to carry enough money to cover all bets – for more on this see the plot of the Ocean’s movies. As Captain Janeway once said “Never bet against the house.”
In games like horse racing, casino poker, and the lottery, all bets are pooled first so that the house can take a cut (or rake). The remaining money is then what players have the opportunity to win. You’re probably most familiar with this from experience of news stories on big ticket lottery games. A jackpot may be 200 million dollars one week – if no one wins and people continue buying tickets it may be 220 million the next. The jackpot is increasing because the pooled money is increasing. When a winner hits they might have the sole winning ticket, or they might have to split that jackpot with others who also share that winning ticket (or ‘close’ tickets, like 5 of 6 numbers).
This is a good way to get a conceptual grip on horse racing. When you play the lottery or poker, the house doesn’t determine what you can win. When you buy a lottery ticket you’re making a bet that your number will be drawn. Unlike roulette, there is no fixed amount you will win per dollar bet in the lottery, and betting more on the same number doesn’t always increase your payout – if you buy $10,000 worth of the same ticket you’re not going to win 10,000 times as much money. If you’re the sole winner you’re actually going to win the same amount (accounting for the fact that you also increased the size of the jackpot by buying more tickets). If you’re winner with others you will win more shares of the whole, but the total amount will still be capped.
Horse racing is incredibly similar to the lottery in this way. You’re not betting against the house, the house is simply acting as bookkeeper (and taking a cut of somewhere around 17% for that work). You’re betting against all the other people who are also betting.
Think of a horse race with 10 horses, and a 1-digit lottery pick-em ticket. In each you have 10 choices for betting – 10 horses in the race and 10 single digit numbers in the lottery.
Now, this produces a weird lottery, as roughly 10% of those who enter will win. If 100 people each buy $1 ticket randomly, we’d expect around 10 to buy any given ticket. That means we’d also expect about 10 people to win their share of the $100, after the house cut (let’s call it 17%, or $17). There’s now $83 to be divided between 10 people, so each person wins $8.30 from their $1 bet.
After all tickets were bought, and the house closed betting, they could issue payout tables of what share of the payout would be given to any outcome based on what tickets were bought and how many people were splitting the pool for each result.
That is horse racing.
Well, the difference is that in our lottery there’s an equal chance of any number being drawn, and so people purchase their tickets without any sort of overall pattern. In horse racing, however, some horses are known to be better than others, so more people will bet on them. Imagine the above lottery example if news was leaked that the number 5 was the one that was going to be drawn. Say that this caused almost everyone (99 people) to bet on number 5. If 5 did in fact come up, 99 people would be dividing the post-take pool ($83), and earning about $0.84 – actually losing $0.16.
Say that one person likes voting for the underdog and bets on the number 8, and against predictions it is 8 that is drawn. That person wins the whole post-take pool and walks away with $83 for their $1 bet.
This is what you hope for when betting on horses – that you make a winning bet that no one else has made. Usually this occurs because you bet on, well, a horse that shouldn’t have won.
The other big difference is that horse racing has a whole assortment of bets that you can make. What we’ve discussed so far are straight win bets where you have to pick the winner of the race. In terms of simple bets there are also those where you pick a horse and win if it comes in first or second (place bets), or first second or third (show bets). This increase in the allowed error of your prediction comes at a cost – a drastically reduced share of the winnings. The rest of what I’ll talk about today assumes that you only ever make WIN bets, and not place or show bets.
Beyond this, there are also what are known as exotic bets. How would you feel learning calculus before having a good grip on algebra? How about this: what’s one of the main things that makes solid state drives better than traditional hard disc drives? Less moving parts. With less moving parts you have less parts that can go wrong. Exotic bets in a horse race are full of moving parts.
Looking at this as a statistician I’ve already given my best advice: don’t bet on horses unless you know something about the odds that others don’t (like a secret injury, or secret horse-rocket surgery). If you’re going to bet, though, my advice would be to stick to simple bets for a while, and especially straight win bets, none of the place or show stuff.
That gets us to the stats for the week. What I wanted to take a look at is actually a quote from the character Tom Haverford on the NBC show “Parks and Recreation”:
“When I bet on horses, I never lose. Why? I bet on all the horses.”
– Episode 4.12, “Campaign Ad”
It’s a good joke, and it made me laugh while watching the show, but it also made me think about if that strategy could possibly hold any truth. In a game like roulette the math is pretty simple. There are 37 or 38 positions on the wheel, and betting on any given space pays out 36:1. If you make a bet on every space on the board you’ll lose money every time. It’s mathematically impossible for you to make money in that way. This is because the odds are set by the house to make sure that – on average – the house wins. This house motivation isn’t present in pooled bets – as long as bets are being made the house will always get their cut.
The odds that you see on a board at the track are the odds as they would work out if no more bets were taken. This is why when looking at historic odds you’ll find ‘Morning Line Odds’ as well as ‘Actual Odds’. Back when this all had to be done by hand the odds weren’t calculated continuously, and the house only had a few chances to sit down and do all the math. One of them was the night before the race, which then created the morning line odds, and are used as an approximation. The other was after final bets, and produced the actual payout odds.
There are a lot of horse races every year, so to keep this as digestible as possible I’m only going to focus on one of the biggest – the Kentucky Derby. While this also drastically increases my ability to find historic records, horse racing records of this sort don’t seem to be archived nearly as well as NFL records. I’ve spent some time trying to find historic odds and payouts, and unfortunately only found full data on all contenders back to 2007. I was able to find actual odds for winning horses back to 1985. I’d like a larger data set, but hopefully this gives us something to think about.
To reiterate, what I’m curious about is what happens if you simply bet on every horse in the race. You’re always going to win, but what does it take to make up for that fact that you’re also holding a bunch of losing tickets?
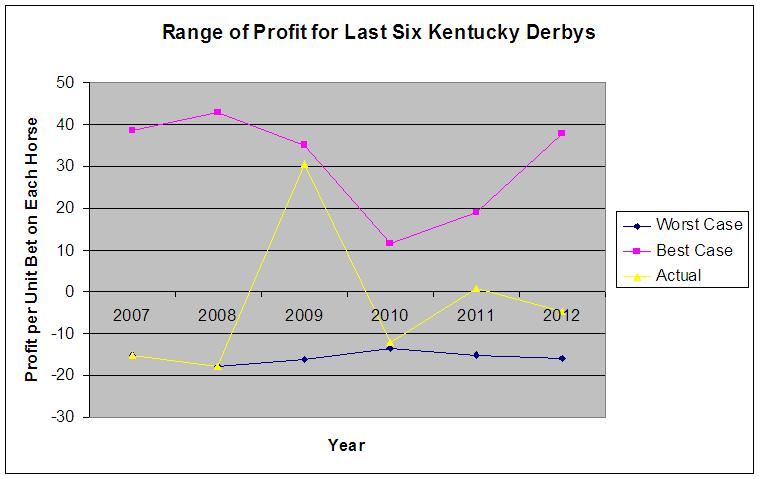
Somewhere around 20 horses take part in the Kentucky Derby, so you’re going to have to somewhere around 20 tickets. What will those 20 tickets get you? Well, here’s a graph of the odds you’d have faced in the last 6 Kentucky Derbys:
Some years are clearly better than others, and in three of the six years the favorite or near favorite won the race. These years (2007, 2008, and 2010) are bad for this strategy, as what you want is something like 2009 where an unexpected horse wins. We still have to factor in what you paid on losing tickets, though, which we can do by shifting the values of the y-axis:
Same lines, but now we can clearly see that the worst case for this system (where the favorite wins) always loses money, and the best case always makes money (though it’s admittedly rare). Only two of the six years would have turned an actual profit, and one of them would have been pretty nice ($30 profit for every block of 20 $1 tickets).
Now, this is only if you can find a place to get $1 tickets. From what I’ve been able to figure out the normal minimum bet is $2 for a WPS (win/place/show) ticket. This is where it starts to get costly. I was able to find odds to the dollar back to 2007 (hence the above graphs), but historical data is much easier to find on Win payout for a $2 ticket, so for full analysis I’ll be assuming you’re buying $2 tickets on all horses.
I was able to piece together the Win ticket payout on a $2 bet for the winning horse all the way back to 1985. Here’s what the second graph looks like if we extend the yellow line back to 1985 under those conditions:
In a majority of these years (1985, 87, 88, 89, 90, 91, 93, 94, 96, 97, 98, 2000, 01, 03, 04, 06, 07, 08, 10, & 12) you’d take a bit of a hit due to a favorite or near favorite winning. In 1992 you’d basically break even. In some other years (1986, 95, 2002, and 11) you’d win a small amount, less than $20 profit for every set of tickets you bought (which is roughly $25-40 for the set). That means that these 6 years would net you less than a 2:1 return on your investment.
Now, in one last set of years (1999, 2005, and 09) you’d make back more than $20 profit for every set of tickets, giving you better than a 1.5:1 return on your investment. In the best years (2005 and 2009), you’d make over $60 profit for every $40 invested, or still just a bit better than a 2.5:1 return.
That’s a little less than impressive – remember that in roulette we were talking about 36:1 returns. My biggest takeaway from this graph seems to be that the cumulative absolute value of the peaks doesn’t seem to make up for the cumulative absolute value of the valleys. Well, we can graph that too:
So, that’s hardly surprising. In most gambling the odds are clearly stacked against you, and the best strategy is taking advantage of random noise in data trends to win some money and quickly get out of the game. The longer you play roulette the more money you are guaranteed to lose. The same appears to hold here. You’re looking to get in on this curve on an upswing – like 1995, 1999, 2005, or 2011, and then quit while you’re ahead.
If you’d been making a $2 bet on every horse in every Kentucky Derby since 1985, at this point you’d have lost just around $175.
That might seem like the punchline, and it sort of is. But there’s one more thing that has come to mind while doing this.
To bet $2 on every horse in the Kentucky Derby from 1985 to 2012 (28 races), you’d need $982 dollars. Now, that might seem like a lot, but that’s the most amount of money you could possibly lose if you never won a single race. We’ve already figured out that you’re never going to lose a race, you’re simply going to win less than what’s needed to cover all your bets.
Without numbers on the full actual odds for Derbys before 2007 I can’t run the math on what you’re actually capable of losing. All we know at this point is that it’s less than $982 dollars. If a far and away favorite – the worst case in my data is a 2:1 favorite in 2008 – won every year for the last 28 years (at which point they’d probably cancel or rig the Derby), you’d still only have lost $870 dollars ($982 dollars bet plus $112 recovered on winning bets).
For the absolute worst case risk of less than $900 dollars ($31.07 a year), you’ve just won 28 straight Kentucky Derbys. You’ve just held up the winning ticket for Mine That Bird and Giacomo. You’re basically biding time waiting for huge upsets that could drive crazy profits, knowing full well that they might simply never hit. Every time you hear someone saying “I wish I could go back to the beginning of the season, put some money on the Cubbies!”, you’ve just cashed in, and you should get out (but you won’t). You win every upset because you’ve bet on every upset. There’s no prediction, there’s no guesswork, simply taking advantage of a betting structure where you’re not betting against the house, but betting into a system with an ambivalent house and an interesting consumer driven odds structure.
Are there safer bets? Certainly! I’ve already told you that you shouldn’t gamble. I’ve shown you that you’re going to lose money in the long run. But how about putting your money in the bank in 1985? Compound interest over the course of 28 years should really grow that $870 dollars, right?
Well, it would, but there’s something to be said about the excitement of it all. There’s certainly something to be said about holding the winning ticket to every Kentucky Derby for 28 years. Maybe it’s just a weird ‘impress your friends’ trick, but there’s certainly worse places to drop nine hundred dollars (and again, that’s worst case – if you’d been doing it from 1985-present you’ve actually only lost $175 or $6.25 a year).
I wasn’t expecting the Tom Haverford betting strategy to hold any water whatsoever, but it curiously doesn’t really seem to be as bad as I might have first thought. You’re not going to get rich, but you’re not going to get poor either. If you do it long enough you’re at the very least going to have a cool story to tell your friends at the low cost of only $6.25 a year.
You’ve certainly heard the quote (whose original source I can’t determine) “Gambling is a tax on those who are bad at math”. Perhaps this method fits more into the Pasteur saying “Chance favors the prepared mind.”
Maybe in the end, Tom Haverford actually said it best:
“When I bet on horses, I never lose. Why? I bet on all the horses.”
I’ll let you know how it goes next May.