Over the span of my life I have played a lot of Tetris. I actually just sat down and tried to figure out when I might have reasonably played my first game of Tetris, and let’s just say it was a very long time ago.
I’m not sure I even want to start coming up with a reasonable estimate for the number of hours I’ve played Tetris, because it’s not likely to be best measured in hours (or even days). I’m sure it would be even worse if we put it into the metric of “if all the [thing] I had done in my life was my full time job, how long would that job last?” Let’s just say I’m sure I’ve knocked out at least a few 40-hour work weeks.
We’re not here to evaluate my life choices, though, we’re here to talk about Tetris. Before we continue too far I should also say I’m somewhat of a (Nintendo) Tetris purist. I’m not going to say that we need to go back to something that will run on a Soviet DVK-2,

But I will say that there’s really no need to go much further than a game that was for all intents perfectly executed to what it needed to be. To put it in the words of Spock in Wrath of Khan -while lamenting the fact that Kirk allowed himself to be promoted to Admiral out of the role of Captain – “Commanding a starship is your first, best destiny. Anything else is a waste of material.”
Tetris is meant to be Tetris. This is Tetris:

Anything else is a waste of material. Anything else is like bedazzling the Mona Lisa.
Side note, I just thought that up but couldn’t help but google it. And…someone has actually bedazzled the Mona Lisa.
Anyway, we can talk about Tetris, but if you want a version where you can press a button to quick drop (in Tetris vernacular “hard drop”), or you want to be able to rotate pieces when they’re against the wall and don’t have room (“wall kick”), or you want to see where the piece would be if it were to keep falling where it is (“ghost piece”), or you want to be able to spin pieces to slow their descent (“easy spin” or “infinite spin”), or you want to be able to hold a piece and/or swap a piece into some sort of reserve (“cheating”), well, we’re playing different games.
And you’re playing the one designed for toddlers. Baby’s first Tetris, perhaps.
Sorry, am I being too hard here?
No. No, I don’t think so. But let’s get to the actual point here.
You can see in the above image that Tetris is happy to give you some numbers on what you’re doing. It’s not really the most efficient to look at these numbers during a game and plan for pieces that might be coming, but it’s interesting to look at after the fact. “Oh, that’s why I lost – I didn’t get enough square pieces” (said no one ever).
Except we’re really pushing for some Tetris-speak today, so instead of square pieces we’ll call them O pieces. Yep, that’s their letter-association name. From top to bottom in the above picture we have T, J, Z, O, S, L, I pieces.
Let’s make it a little easier:

Okay, so now we’re all on the same page.
If you have said anything at the end of the game while looking at the stats, it was probably something relating to your lack (or perceived but unsubstantiated) lack of straight “I” pieces.
Everything I’ve read would tend to indicate that the distribution of Tetris pieces (I’m sorry, “tetrominos“) to be random (if not randomly deterministic).
By the way, don’t mistake that sentence as simple – those are two starts to some pretty deep wiki-spirals.
If the pieces are random, and you play forever (can you play Tetris forever?), you should get roughly a uniform distribution across the types of pieces. How uniform does uniform really have to be to be considered uniform, though?
I’ve been playing and recording a game or two here and there, but mostly recording the stats from having others play. All this has produced the following RAW DATA:

From this we can also calculate the proportions of pieces for each game.
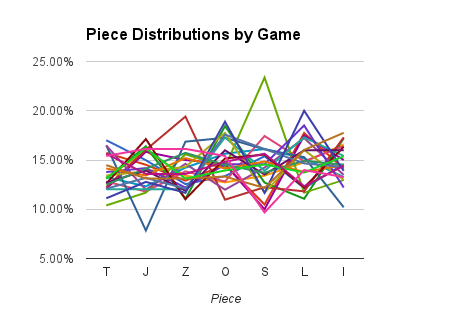
This shows the relative distributions for each game. Other than one game with way too many S pieces and one game with way too few J pieces, things do seem to be in a fairly tight range. We can collapse this down to just means to get a feel if this bit of noise cancels out.
.png)
We can see that things look fairly uniform, though it’s hard to tell exactly what the expected levels are. Changing the scaling to bias lets us see what percentage of pieces we can expect above or below the expected uniform distribution per game:

The bias is quite small, and even with these fairly large numbers of pieces (>6700) a chi-square test of association fails to show a deviation from a random distribution. [ x2 (6) = 9.260, p = 0.16 ]
Oddly, the most common piece in this data seems to be the piece we’re always looking for (the “I”), but this does seem to just be a blip in otherwise random piece distribution. I guess there’s not really any reason to complain, at least overall, unless I want to complain about having too many of the best piece (and for no reason).
Anyway, why are you still reading this and not playing Tetris?






