Hi everyone – today I wanted to put together a fairly quick post about some of the resources I’ve found in that past year that I’ve found interesting (and occasionally useful) in putting together some of the posts on this blog. I’ve also found a lot of resources that I haven’t fully utilized (yet), but figured it might be useful to share. Anyway, here you go:
Reddit Insight – “We downloaded the Reddit”
Who doesn’t love Reddit when you’re looking for something to kill a few minutes/hours/days? If you’re bored of Reddit, though, you can use this site to kill time while looking at data generated by and about Reddit. Meta time killing, if you will. There’s some cool tools, and who doesn’t like word clouds?
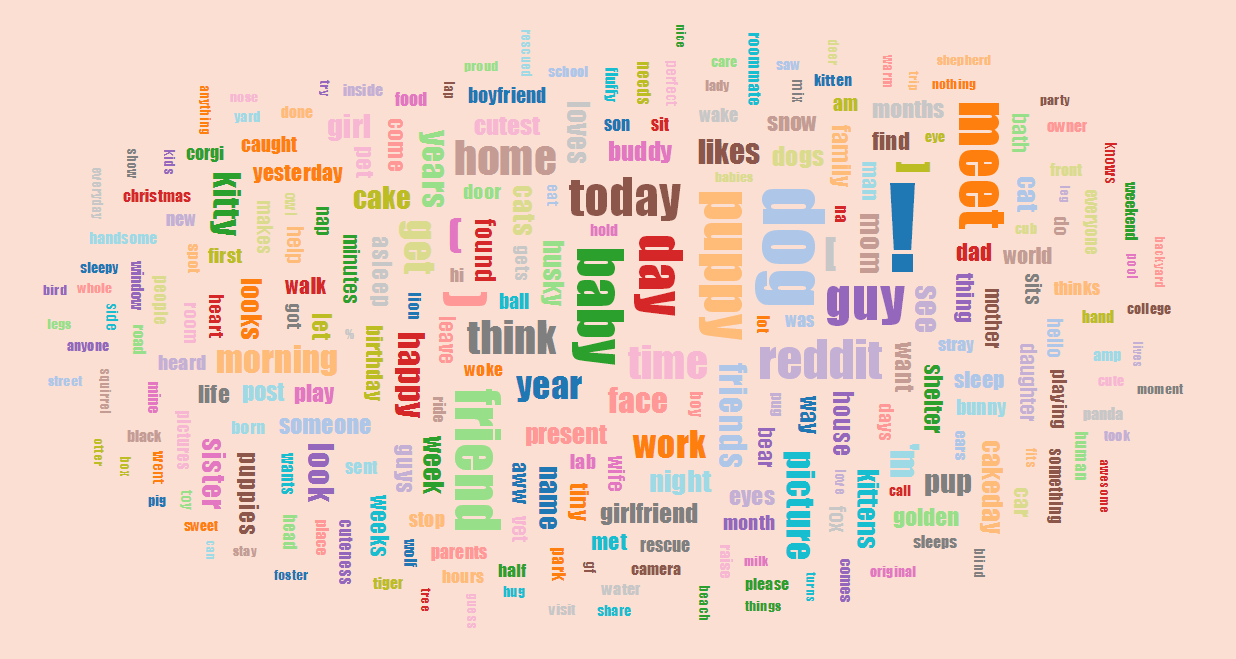 |
| Aww subreddit word cloud |
Wikipedia Statistics (Overall) – ““WP:ST” redirects here.“
http://en.wikipedia.org/wiki/Wikipedia:Statistics
There is a lot of information on Wikipedia, and there is also a lot of information about that information on this page. I don’t know where to begin – this post could just be about this page. How about the top 25 Wikipedia pages from last week?

Wikipedia Special Pages – “This page contains a list of special pages.“
http://en.wikipedia.org/wiki/Special:SpecialPages
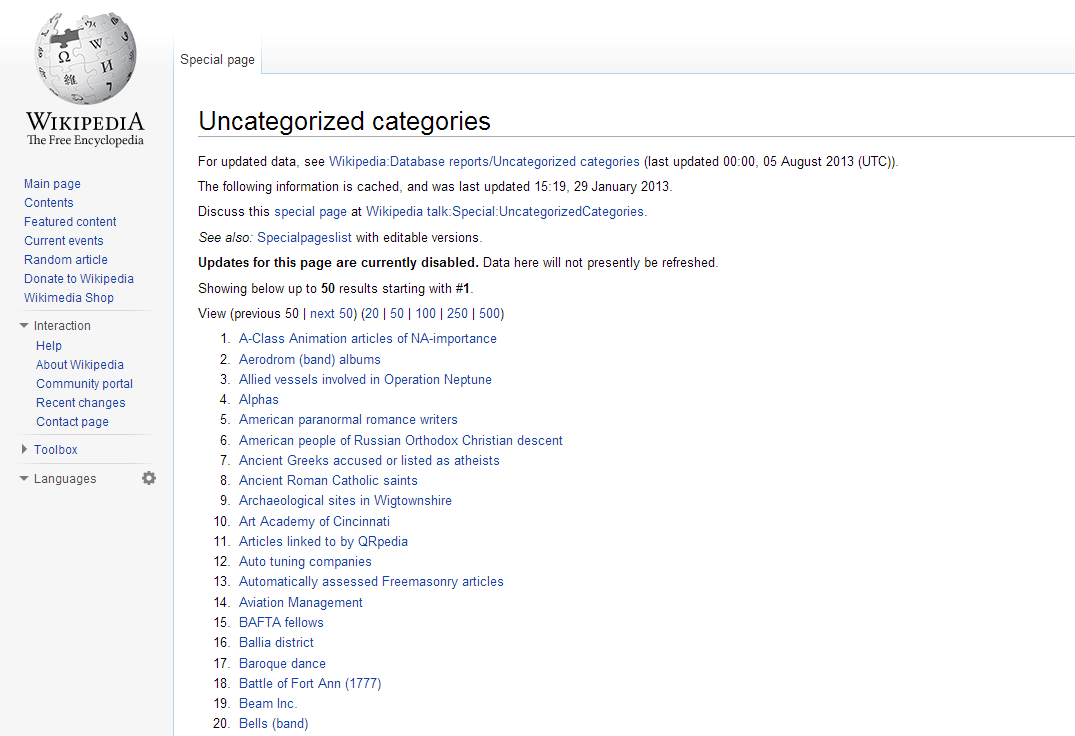
So you think that the last page had a lot of information about Wikipedia, and there’s probably not much more that’s really interesting enough to talk about? Well, welcome to the sub-basement of Wikipedia, where people get together to generate lists of all sorts of things, like Long Pages, Orphaned Pages, and perhaps my favorite list on the internet, that of Uncategorized Categories.
Wikipedia Random Page – “Do you feel lucky, punk?”
http://en.wikipedia.org/wiki/Special:Random
This doesn’t generate any statistics on its own, but I think it’s an interesting page nonetheless. You can certainly run some calculations based on the numbers from other Wikipedia pages, like what your odds are of finding the page you’re looking for on Wikipedia by simply clicking that link (it’s about 1 in 30 million).
So if you’re feeling like learning something, give some Wiki Roulette a try.
Who knows, someday it might be important that you know something about David Alton, Baron Alton of Liverpool.
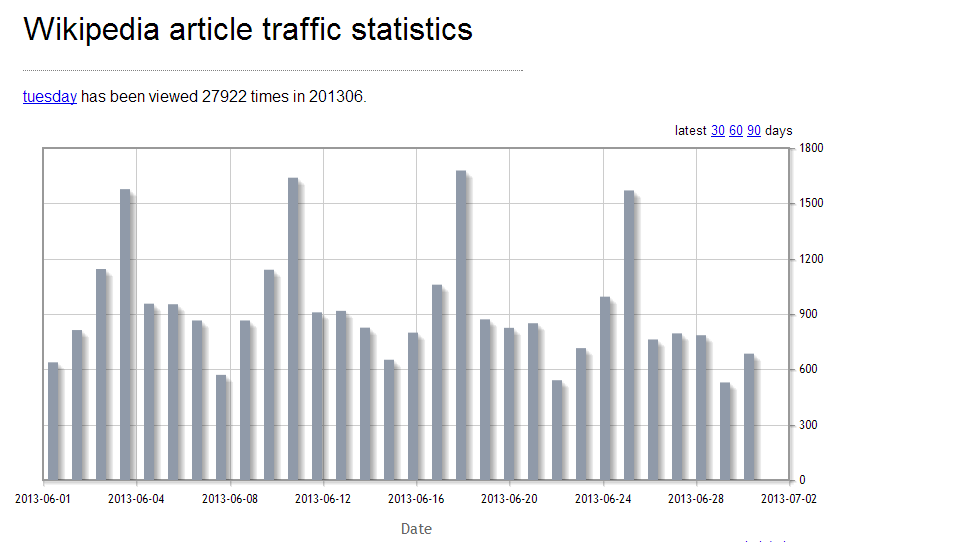
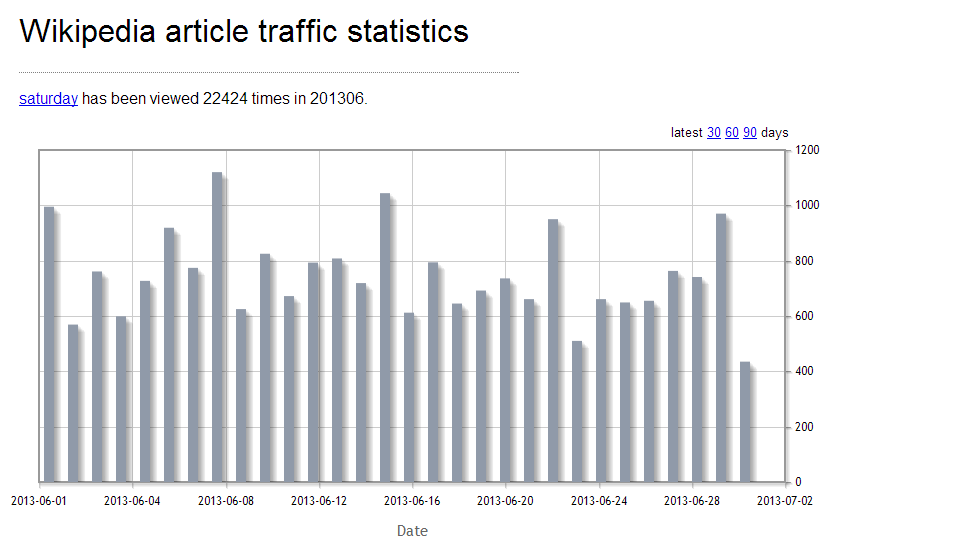
Wikipedia Pageview Stats – “How about you tell me in graph form?”
http://stats.grok.se/en/201306/wikipedia
I swear that a few years ago Wikipedia had some tools built into their own site to look at stats from specific pages, but recently this page has been all that I could find. It’s great if you’re looking for patterns in data, like if people are more likely to look at articles about particular days of the week on those days of the week.





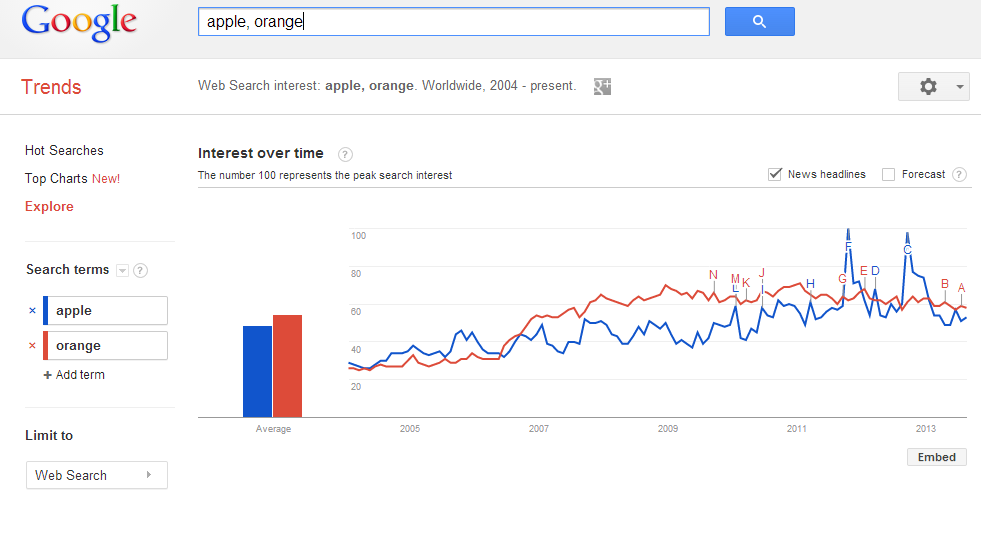
Google Trends – “Two trends enter, one trend leaves”
http://www.google.com/trends/topcharts
Google Trends seems to have two main things going on. The first is the stuff on the main page, which is letting you know what’s trending on Google. Personally, that’s really quite boring. The fun part of Google Trends is pitting two (or more?) topics against each other to see how search volume has compared over some space of time. For instance:
http://www.google.com/trends/explore?q=red%2C+blue#q=red%2C%20blue&cmpt=q
Produces a great graph of search volumes of “red” vs “blue”:

Yes, I know (and you should too – that’s what legends are for!) that red is the blue line and blue is the red line. It’s the order they are put in that matters, and I find the prospect of them switched to be amusing for some reason. So, I’m keeping it.
That said, looks like red started winning sometime around 2008. Some of those letters on the graph might help you pull out why that is, as it links time frames to news stories and the like. It also shows searches that contained these words, etc. It’s a fun tool, especially for those of us who always wondered why people thought it was so hard to compare apples to oranges.
Google Correlate – “Correlating your Googles”
http://www.google.com/trends/correlate
This one is a bit newer to me, but has some cool applications. It lets you see what words are searched for together, or rather which search terms are correlated to any given search term.
For instance, a search for “turkey” reveals that people are very often searching for “turkey stuffing”.

You can also export these results, and do some other stuff with it, I guess? Like I said, this one is relatively new to me, so I’m in the process of thinking of ways to try to use it.
Professional Football (NFL) Stats (1940 to present) – “All the games, and then some”
http://www.pro-football-reference.com/
If you’ve been reading the blog for a while you recognize this site, as it’s the one that I used to look at historic scores in the first week of the season. It has all the outcomes from every NFL game ever played, and some stats from games even before that. There’s…a lot of information.
Professional Baseball (MLB) Stats (1916 to present) – “Like football, but baseball”
http://www.baseball-reference.com/
While I’ve never used it, you can also find stats on all professional baseball games played in the last century or so. Again, it’s a lot of information.
Professional Hockey (NHL) Stats (1987? to present) – “We taped over all the early games”
http://www.hockey-reference.com/
Finally, there’s also a professional hockey version of the last two pages, though for some reason it only extends back to 1987. Maybe they’re working on it? Hard to say.
Twitter Stats – “A constant, never ending stream of information”
I actually had a decent amount of trouble finding any official stats on the Twitter page, as it looks like almost all of the stats generating tools are third-party. Maybe that’s not the case, and I’m looking in the wrong place. If I was going to list one third-party Twitter tool I’d rather list a ton, so maybe that will just wait until a future post.
.png)
.png)