If you’ve been following the news of the last week you might have heard about the recent meteor that was seen (and paparazzied to death) over Russia. While it’s only somewhat statistical (okay, minimally statistical), I figured it would be a fun topic to talk about this week.
On second though, let’s get some stats out of the way up front. You may have heard reporters talking/writing about this meteor impact as a one in one hundred year event. Despite the difficulty of determining these sorts of meteor impacts over oceans (70% of the globe) before we had a satellite network, or of determining these impacts over non-explored portions of the globe before, say, the 1500s (90%?), let’s say that this number is correct based on our 100 years or so of good global record-keeping. I have literally read articles that paint this recent strike as a positive thing due to the fact that something like this shouldn’t happen for another hundred years now that we’ve had our strike during this hundred years.
If you’ve been reading this blog for a while I’m not even going to insult you by explaining how much is wrong with that sort of assumption. Let’s get back to the fun stuff – meteors. (If you’re still wondering why there’s so much wrong with such a claim just google ‘statistical independence’)
There are a few reasons that I find it fun to talk about meteors. First, meteors are cool. That might be enough for some of you. Beyond that, though, I think there’s a lot of great points to learn about meteors and the atmosphere and speeds of things, etc. Did I mention that meteors are cool?
Before we get to deep into it, if you haven’t seen much footage of the actual impact, you can find a whole bunch of videos of it here:
http://say26.com/meteorite-in-russia-all-videos-in-one-place
There’s a lot of information to take away from these videos, actually. It’s pretty fantastic that so many Russians have dash cameras on their cars or trucks – apparently a big part of it is simply the fact that having a documentation of your driving helps out if you find yourself in an accident or pulled over for something you may or may not have done. Makes fighting that traffic ticket in court a whole lot easier.
A pretty good view of what’s happening can be found in the first video on that page, or on YouTube here:
http://www.youtube.com/watch?feature=player_embedded&v=tkzIQ6JlZVw
One of the first things you should take note of is the fact that you see what looks like to be a pretty energetic reentry, but that you don’t hear anything. Are you thinking it’s because the camera is in a car? Well, no.
This is something that has been misrepresented for the better part of the last century – basically as long as we’ve been matching sound to video. Have you ever seen video of an atomic bomb blast from back in the 40s or 50s?
You might be able to picture in your mind what this even looks like – the bright flash and then the rising mushroom cloud. Along with the bright flash you probably also remember a pretty loud explosion.
If you’ve been to a track event started with a pistol and sat way up in the stands, been to a fireworks display from a distance, or watched a thunderstorm for a while, you might understand that this doesn’t really make a lot of sense. In fact, there are exceptionally few surviving clips of atomic tests with correctly matched audio – most footage uses stock explosion noises with the sight and sound of the explosion matched. If you’re interested, more information on the topic can be found here:
http://www.dailymail.co.uk/sciencetech/article-2174289/Ever-heard-sound-nuclear-bomb-going-Historian-unveils-surviving-audio-recordings-blast-1950s-Nevada-tests.html
The reason that you hear thunder some time after you see lightning is due to the differential speeds of light and sound. Light is…pretty fast. It’s usually expressed in meters per second, and every second it actually goes a whole lot of meters. With some rounding for simplicity (don’t worry I’ll use actual numbers for calculations), it’s around 300,000,000 meters. Every second.
Sound, on the other hand, is actually pretty slow. In the same second that light can travel around the Earth seven or so times, sound doesn’t even make it down to the corner store. It takes over four seconds for sound to make it a mile – if sound was running a 5K it would put in a time of just under 15 seconds.
In that same time, light could run over 100,000 marathons.
[One important aside before we continue – the speed of light is usually given as the speed of light in a vacuum. Light does travel slightly slower in atmosphere, but the difference is small enough to be negligible in most cases. The speed of sound in most cases is given at sea level – these are the numbers I’ve used above. The speed of sound does decrease as you travel up through the atmosphere, but – despite the fact it could be applicable here – I’m not going to go into that sort of detail. This will be left up to the ambitious reader.]
This might have been a lot of setup for something you’re already pretty aware of. If something that produces noise happens a distance away from you, the light from the event will reach you before the sound does. That means that you’ll see the event before you hear it. How much earlier? Well, it depends on how far away the event is.
If you’re sitting a dozen or so feet away from your television, the difference between the light and sound coming at you is small enough that you don’t notice any difference. That is, the sound seems to match the image.
If you were watching a drive-in movie screen through binoculars from a mile away and relying on sound produced at the screen itself you’d start to notice that things weren’t matching up. How far off would the audio be at that distance?
In the extreme, if we set off an atomic bomb on the moon, how out of synch would the sound be at that distance?
Well, the first question can be answered, and we’ll do it below. The second is a trick question because sound (unlike light) needs a medium to propagate through; like air or water. There’s no air (or water) between us and the moon (or on the moon), and so no sound waves would propagate from the explosion.
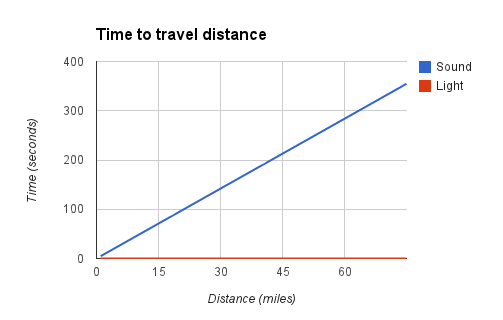
To answer the first question we can start by taking a look at the time it takes sound and light to travel a range of distances.
It’s possible that you’re asking: where’s the line for light? It’s at the bottom – the red line isn’t an axis, it’s the time it takes light to travel these distances. Compared to sound, the difference between light traveling 1 mile and light traveling 75 miles is fairly negligible. Light can travel both of these distances in a fraction of a second.
It takes sound a little over 4 seconds to travel 1 mile. If you’ve ever heard the old rule that you can count the seconds between seeing lightning and hearing thunder then divide by four to figure how many miles away the strike was you now see why that makes sense. For the distances you see and hear lightning the rounding doesn’t really cause any major problems.
Why am I going on about all this when we should be talking about meteors? Well, the fact that so many Russians have dash cameras means that we have a huge supply of data available to us. We can even find a few examples where the incoming meteor is pretty close to directly overhead. Here’s a good example:
http://www.youtube.com/watch?feature=player_embedded&v=odKjwrjIM-k
Since we’re looking at a dash camera we also have a second-by-second time stamp, which is great. You can see that the person who uploaded this clip cut out a part of the middle – the time between seeing the meteor and actually feeling the shock wave. We can figure out the difference here by taking note of when two events occur.
The first is the place in the video where the meteor seems to be directly overhead and most energetic – right around 43:05. The second is when the shock wave hits and knocks some snow off the surrounding buildings. It’s seconds later in the clip as edited, but the time stamp reveals that it was just about a minute and a half later, at 44:35.
Imagine you were watching a thunderstorm and saw some lightning. A minute and a half later you heard the accompanying thunder. You might not even link these two events in your mind – you might associate the thunder with more recent lightning strikes that you may have missed.
Well, unless the thunder sounded like this:
http://www.youtube.com/watch?feature=player_embedded&v=w6uOzFo2MQg#!
From the numbers behind the above graph we can figure out what a minute and a half lag time means – turns out it’s around 19 miles.
I can hear some of you yelling already, even through the internets. You’re using the speed of sound at sea level! Yes, yes I am. I told you that the speed of sound slows as you travel up in the atmosphere, and this meteor was obviously not at sea level. This means that our estimate of 19 miles will be off, though we at least have a decent ballpark estimation.
I can also hear a much smaller contingent of you yelling that things are a lot more complex than that and shock waves have different profiles than sound waves. Well, yes. I was hoping to keep this pretty simple to get across a point, but if you’re so inclined you can learn a bit more here:
http://www.fas.org/sgp/othergov/doe/lanl/pubs/00326956.pdf
and here:
http://en.wikipedia.org/wiki/Shock_wave
19 miles is a bit of a distance. The fact that damage was produced even at this distance is a testament to the amount of energy released from this particular meteor. Current estimates have placed the energy released on the scale of nearly half a megaton of TNT (just under 500 kilotons). Everyone is comparing that to the explosion of “Little Boy”, the atomic bomb dropped on Hiroshima, which checked in at 16 kilotons.
This brings us to some facts about meteors and the atmosphere that are a little less stats-y (not that we’ve been stats heavy to this point).
Let’s start with some simple stuff. We’ve been using the term meteor here, and the use of that term actually carries with it some useful information.
A piece of debris that’s simply floating around in space isn’t a meteor – it’s a meteoroid if it’s fairly small (roughly up to the size of a small car), an asteroid if it’s a bit larger (up to the size of a small moon), and a planetoid if it’s much larger (that’s no moon!).
If any of these things is composed of ice – enough that it grows a tail – it is a comet.
Once one of these things comes in contact with the Earth’s atmosphere (or any atmosphere, really) it becomes a meteor. Thus, what was seen in the Russian sky was a meteor. There are reports that some fragments of the meteor may have been found – if any parts of a meteor survive to the ground those fragments become meteorites.
You’ve also clearly seen the trail left in the sky by the meteor – a trail that persisted for some time. I want you to think about two questions for a moment. The first is why a meteor (or a space shuttle) heats up when it enters Earth’s atmosphere. The second is what causes a trail to be left in the sky behind a meteor such as the one filmed over Russia. Think about both of these for a minute or so.
Okay, so what are you thinking?
Your ideas on this are probably again a bit polluted by a few sources. Mainly movies and TV, I’d bet.
The first question is quite a bit easier, but also one of those that seems to be fairly misunderstood. You might be thinking that meteors (or the space shuttle, etc) heats up on entry (or reentry) due to friction with the air. Friction is actually a very small part of this process – what’s really happening is that the air in front of whatever is entering the atmosphere is being compressed. This is simply due to the fact that air can’t move out of the way of an object fast enough once an object reaches certain speeds. Since it can’t get out of the way it becomes compressed.
If you’ve ever sat around and figured out how your refrigerator works (I would suggest it as a fun thought experiment as well) you might recognize what’s happening as a bit of a reverse of that process. As air is compressed it becomes hotter. When a lot of air is compressed really quickly it becomes really hot. This is what’s heating meteors and space shuttles, etc.
Looking to kill a bit more time? Randall Munroe of XKCD has a really cool post on what would happen to a diamond meteor upon entry at different speeds here:
http://what-if.xkcd.com/20/
The space shuttle doesn’t burn up on reentry due to some pretty sophisticated heat shielding, but meteors aren’t so lucky. This heat causes differential stress on parts of the meteor and it begins to burn up and break up. This is why many meteors never become meteorites.
This leads to the second question, which I’m going admit I’m not sure that I have a solid answer on – the internets don’t seem to address it. I’m suspecting that many of you are thinking that the trail behind a meteor is a smoke trail. I can see how this idea would get planted in our minds – movies and television have given us plenty of examples of things on fire plummeting toward the ground with smoke trailing behind them. Nicolas Cage’s stellar performance in Con Air, anyone?
Like I said, I’m having trouble figuring this out with any actual sources, but it doesn’t seem that a meteor streaking through the sky is the best place for normal combustion to take place. Moreover, you’ll notice that trails behind meteors are (from what I’ve found) universally white – combustion of different components of different meteors would presumably lead to smoke at least occasionally displaying darker shades. You know, different shades like you’re probably familiar with from movies like Deep Impact where you see a plume of dark smoke trailing the meteor as it streaks through the atmosphere. Example here:
http://www.top10films.co.uk/img/deep-impact-disaster-movie.jpg
What is the alternative? Well, cloud formation.
If you remember your grade school science fairs you might be familiar with the old ‘make a cloud in a bottle’ experiment.’ If not, a good example is here:
http://weather.about.com/od/under10minutes/ht/cloudbottle.htm
Much of cloud formation relies on the compression and decompression of air with at least some water vapor content and dust particles. We’ve already discussed how a meteor compresses air (which is free to decompress in the immediate wake of the meteor) – as long as local humidity is above zero the meteor is also producing a reasonable share of dust through the breaking/burning up process.
Similar to how airplanes in high atmosphere form contrails it seems that meteors might be leaving a trail that’s nothing more than clouds formed by their fairly violent passage through the air. Like I said, I can’t find this in any of the intertubes, so it’d be interesting to have a discussion if people have other thoughts.
One other thing before we go – in all the coverage of this meteor strike I’ve only seen one or two articles that discussed the angle of entry of this meteor. You can probably figure it out from the name, but angle of entry relates to the angle that something enters the atmosphere. The extreme ends would be directly perpendicular to the ground (think Felix Baumgartner skydiving from space) and directly parallel to the ground (which might cause an object to even deflect off the atmosphere – think satellites that are in orbits that are allowed to decay).
This meteor was much closer to the second – you can tell pretty clearly from the videos of it that it had a shallow entry (it has been estimated at less than 20 degrees). The angle of entry is important because it is one of the main determinants of how long something spends in atmosphere before it reaches the ground. The numbers that I’ve seen seem to indicate that this particular meteor spent over 30 seconds in the atmosphere before it broke up. The fact that it had 30 seconds of time in atmosphere was only because it was traveling at such a shallow angle – imagine if it had hit the atmosphere with an angle of entry closer to Felix Baumgartner.
Well, to do some math on this we need to decide where the edge of space is. As you travel up in the atmosphere, air gets thinner, and eventually there’s no air. It’s not a hard edge, though, it’s a slow gradient, so it’s tricky to decide when a small amount of air is different from no air. Most estimates that I’ve found seem to be in the 75-100 mile range. This is good enough for some quick estimation.
The Russian meteor entered Earth’s atmosphere at a speed of around 11 miles per second. If it was taking the shortest path through the atmosphere (straight on, perpendicular to the ground), it would reach the ground in somewhere around 9 seconds (if we’re calling space 100 miles up). If we go with 75 miles to the edge of space we’re looking at closer to 7 seconds. Sure, the air is slowing it as it descends, but this 9 seconds is a lot less than 30. I’ll also cede the fact that traveling at a steeper angle through the atmosphere creates a quicker pass through pressure gradients and might have caused breakup faster.
Still, if this meteor had entered at such an angle there’s a real chance that it may have impacted the ground before it broke up. The energy released in atmosphere was enough to blow out windows and doors 19 miles away – if this energy were transferred all at once to a stationary object (like the ground), well, then we’d really have something like Hiroshima on our hands. The fact that some portion of the population says ‘well, at least we don’t have to worry about it for another 100 years’ flies right in the face of what we should actually be taking out of this.
Anyway, that seems like as good a place as any to leave you with something to think about. Thanks for all the dash cams, Russia.




{kind=link}