Today happens to be Halloween, and the fact that it fell on a Wednesday this year convinced me to take a try at putting together a special Halloween post. It will be 6 years before that happens again (remind me to do a post on the regression of dates and days of the week), so it seemed like the right time.
I’d like to say that I spent a lot of time thinking about a really good idea, but I have to say that I’ve found the most interesting ideas are often those that come to mind fairly quickly. There’s a subtle quality to simplicity.
There’s a good chance you might be reading this after Halloween is over, knee deep in the spoils of war: Halloween candy.
That got me thinking – what if we didn’t look at trick or treating as a modern method of gluttony and endulgence, but of a viable hunter/gatherer method of procuring a food source? Another way to think about it is: What if the movie Encino Man had taken place in late October and Pauly Shore and Samwise Gamgee hadn’t been around to help him out?
Well, Brendan Frasier might have started foraging in a world where every house was handing out some of the most calorically dense food he’d ever encountered. What does that mean to Paleolithic Man or a young child? HOARD FOOD.
Just how good of a strategy is this, if you were in fact a child of the Paleolithic Age? A child of the modern age on Halloween will no doubt tell you that biggest bag of candy is best bag of candy. A child of the modern age two weeks later will tell you that the candy is still good and of course they will still (begrudgingly) eat it.
So what sort of net caloric gain can we expect from trick or treating? The easier part is our caloric deficit by actually getting up and going outdoors to walk around and collect things. The problem is that calories burned while walking is exceptionally dependent on a lot of different factors that are going to vary a lot, not only in the overall population but even in the child population.
I’m going to make some reasonable guesses here, and say that on average the pace is fairly slow – there’s a lot of walking, but also a lot of waiting at doors. The best bet for a kid is suburbia, where houses are pretty close together, so that the time spent waiting and the time spent walking is probably pretty well balanced. Given that there’s a mix of walking, (child) running, and dead stop, I’m going to assume that the average pace is somewhere around 2mph, which means that a child should be burning somewhere around 100-150 calories an hour.
There’s an interesting classical mechanics reverse rocket fuel problem here, as children are also collecting mass in the form of candy that they have to carry through the rest of the evening. If anyone wants to tackle that one it would be a great physics problem, but for the purposes of this post the noise already inherent in estimates is more than enough to wash out any extra precision that would be gained from such an exercise.
So, let’s say kids are burning around 125 calories an hour through the process of trick or treating. Earn and eat one Reese’s Peanut Butter Pumpkin (90 calories) every 45 minutes and you’re now just about calorie neutral.
You’re not going to spend all that time just collecting and eating one peanut butter pumpkin, though – what else should you reasonably expect to get?
Here’s there the real guesswork begins. I have a brief aside about the dangers of relying on information found on the internet without going to source. A search of ‘most popular halloween candy’ brings up a lot of hits, and it’s easy to find websites that claim to have just that. They don’t put any context on it, and it’s easy to believe that these lists represent the most likely candy to be given out to children.
The usual top of those lists? Reese’s Peanut Butter Cups. I was once a kid, and I am immediately skeptical of this. I never once poured out my bag of candy to find a overwhelming pile of peanut butter cups. Well, let’s dig to source.
Most websites with this same list don’t mention where it came from at all, but I eventually found one that did. The list of ‘Most Popular Halloween Candy’ could eventually be tracked back to a site that presented the same list as Voted Most Popular Halloween Candy, from a poll that they had held.
It seems like most leads I was able to find eventually get down to something like this. There are several articles whose titles are things like “Best Selling Halloween Candy”, but then immediately talk about popularity and just which candy is best. I don’t know what I was really expecting when it came to Halloween-centric candy articles, but it’s pretty disheartening.
Given this lack of information, the best way to really figure this out would be to simply have kids, send them out trick or treating, and then catalog what was in the bag at the end of the night. I’m going to consider that a little too much work for one post, so instead I’m going to try to work with some averages.
I’m also going to try to work from memory and think back to the things that I remember getting back in the day. I think this list pretty much covers it, complete with the most accurate calorie information I could find:
100 Grand – 95
3 Musketeers – 63
Almond Joy – 91
Baby Ruth – 85
Butterfinger – 100
Candy Corn (11 pieces) – 70
Caramels (2 pieces) – 80
Dots – 70
Heath Bar – 77
Hershey’s Chocolate Bar – 67
Hershey’s Kisses (3 pieces) – 78
Junior Mints – 50
Kit Kats – 73
Laffy Taffy – 32
M&M’s – 90
M&M’s Peanut – 93
Mike & Ike – 50
Milk Duds – 40
Milky Way – 76
Mounds – 92
Mr Goodbar – 90
Nerds – 50
Nestle Crunch – 51
Pay Day – 90
Pixie Stix (3 sticks) – 25
Reese’s Peanut Butter Cup (medium) – 88
Reese’s Peanut Butter Pumpkin -90
Skittles – 80
Snickers – 72
Sweet Tarts – 10
Tootsie Rolls (3 pieces) – 70
Twix Carmel – 50
Twix Peanut Butter – 50
Twizzlers – 64
Whoppers – 100
All the calories are for ‘fun size’ or ‘snack size’ bars. In terms of bar candy, these are the ones that are actually rectangular, not the square ones – I’m assuming if someone is giving out the smaller square ones you’d get two of them, which adds up to the larger bar. Some of the items on the list also have notes for those that are unlikely to just receive one of (like Hershey’s Kisses).
A histogram of these candies reveals that things are generally all in the same area.
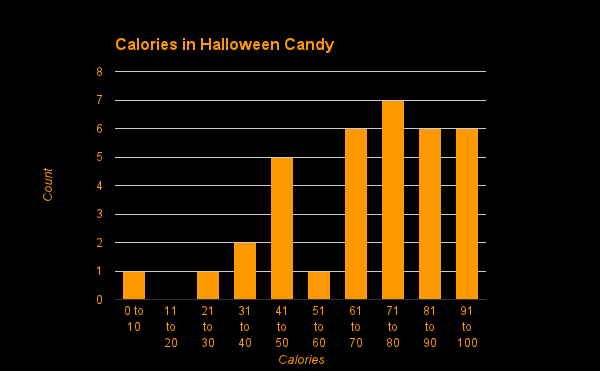.png)
Sweet Tarts are the oddity, with only 10 calories in the Halloween sized portion. That said, the mean and median are almost identical (70 and 73), so I’m just going to go with those. If I doubled things for Sweet Tarts on the assumption you probably wouldn’t just get one thing of Sweet Tarts then the mean would be a touch closer to the median anyway. Some of these candies might be more represented in a standard take, but hopefully most of that should wash out. I’m going to assume that the majority of houses give out one of these things from the list (60%), some houses give out double (30%), and a small number give out triple (10%).
If we weight houses based on these numbers we come up with an average take per house of just about 110 calories.
This means that we now know how many calories you will burn per unit time, how many calories you will collect per house (on average), and all that remains is how many houses you can trick or treat at per unit time.
This is the place that things should vary the most. If you live in a neighborhood where the houses are closer together (or farther apart), you might be able to change this number around a bit. The type of neighborhood I’m going to work from gives me about a house every minute, taking into account walking, waiting, and getting the candy.
We now have enough data to do some math – if you’re able to get to 60 houses an hour, and each house gives you an average of 110 calories of candy, and every hour you spend 125 calories in work, then you’re coming up with a net gain of about 6,475 calories worth of candy per hour.
Not too bad. Considering that kids usually trick or treat for 2-3 hours, that means that you have the potential to be pulling down just a little more than 500 calories short of 20K: 19,425 calories. If you ate nothing but candy, and every day ate your daily allotment of 2,000 calories, you’d still be set for over a week. It’s likely you wouldn’t be feeling that great by then, but if we go back to Brendon Frasier I’m betting he wouldn’t care as much. Food is food.
So, how much could our hunter/gatherer ancestors pull down if they were really stockpiling for the winter?
The candy they get at each house shouldn’t change, so the things they have the ability to change are pace and total time.
In the above example we assumed that little kids can only move so fast, and are also burdened by slowest members of the group, whether those are even younger children or parents who want to walk at a more casual pace.
Living in a hunter/gatherer society would likely create individuals who were much more willing and capable to pick up the pace. An all out sprint is probably unsustainable, but it’s a lot easier to believe that our trick-or-treaters could maintain a light jog of about 6mph. That’s only a 10-minute mile and there are plenty of opportunities for rest while waiting at the door, so I don’t think it’s too unreasonable.
If you’ve never watched an analog clock tick away 30 seconds, I suggest you do it now. It’s actually a pretty long time, for what it’s worth. I’m going to assume that a job of 6mph between houses in the above scenario will cut time per house in half, or double the number of houses that you can trick or treat at in any given time frame.
It also comes at a cost – a jog is going to burn considerably more calories than our casual stroll. How many? Well, if we’re also assuming that we’re now talking about full grown adults, and they’re still spending half the time waiting and half the time jogging, then they’re going to burn somewhere around 300 calories per hour (three small butterfingers).
That said, they’re also collecting double the calories per hour by getting to twice as many houses. The net result? 12,900 calories earned per hour.
If such an individual is motivated, they might also find a town that has longer trick or treating hours – let’s say a 4 hour window. During that four hour window they could net over fifty thousand calories – 51,600 to be exact.
That’s almost a month of 2,000 calorie candy days. If you were willing to ration and only eat 1,000 calories per day you could eke out seven weeks of sustenance (if it could be called that).
Anyway, Hollywood, that’s my pitch for Encino Man 2: Brendon Frasier Saves Halloween.
Happy Halloween, everyone!













{kind=link}
{kind=link}
{kind=link}
{kind=link}